Bei der Wartung von Cloud-Services kommt es meist zu unvorhersehbaren Ausfällen bei den Angeboten der Cloud-Kunden. Es gibt verschiedene Ansätze, um dieses Problem zu lösen, die vor allem davon abhängig sind, welche Software in der Cloud-Umgebung läuft. Die meiste heute eingesetzte Enterprise-Software kann aber auf solche Ausfallzeiten nicht selbsttätig reagieren. Diese Software wurde einfach nicht für die Cloud entwickelt, weswegen wir sie als „klassische Software“ bezeichnen. Für Wartungsarbeiten muss die virtuelle Maschine (VM), auf der solche Software läuft, extra heruntergefahren werden, um Fehler bei der Datenspeicherung zu vermeiden.
Bei Global Access setzen wir hingegen eine Technologie ein, die es uns ermöglicht, eine laufende VM ohne Ausfallzeit an einen anderen Ort zu verlagern. Das Ergebnis: Unsere Kunden bemerken nicht einmal, wenn wir Wartungsarbeiten durchführen.
Um unsere Cloud-Infrastruktur immer auf dem neuesten und höchsten Standard zu halten, müssen unsere Techniker regelmäßig verschiedene Komponenten überarbeiten. Dafür benutzen wir einen Hypervisor, der es uns ermöglicht, virtuelle Maschinen nahtlos zu verschieben – sogar in ein anderes Rechenzentrum. Die meisten Cloud-Anbieter, insbesondere Microsoft Azure und Amazon Web Services setzen einen anderen Hypervisor ein, ihre Technologie ist deswegen nicht zu solchen VM-Transfers fähig. Kunden dieser Anbieter bleibt nichts anderes übrig, als ihre VM herunter zu fahren, sie in ein anderes Rechenzentrum zu kopieren und anschließend dort die Kopie wieder zu starten. Dieser Prozess kann allerdings einige Stunden oder sogar Tage dauern.
Hier zeigen wir, wie bei Global Access unsere interne Infrastruktur mittels der genannten Technologie gewartet wird.
Die Hardware-Struktur
Unsere Infrastruktur ist so angelegt, dass sie kleinere und größere Ausfälle in einem Rechenzentrum auffangen kann – selbst den Ausfall eines gesamten Rechenzentrums. Solche Ausfälle mögen selten sein, aber sie werden früher oder später jeden treffen.
Wir betreiben unsere internen virtuellen Maschinen auf einem Cluster von vier Hosts: esx38 und esx39 in einem Rechenzentrum, esx40 und esx41 in dem anderen. Die Cluster für unsere Kunden bestehen sogar aus noch mehr Servern, aber für die Veranschaulichung dieses Tests reicht der Cluster aus vier.
Wenn wir zum Beispiel an der Hardware arbeiten oder Sicherheitsupdates auf einem Host installieren müssen, verlagern wir alle virtuellen Maschinen von diesem Server auf einen anderen. Wenn eine Wartung der Stromversorgung notwendig ist, verschieben wir alle VM von einem Rechenzentrum ins andere.
Um hier eine typische Wartungssituation zu zeigen, arbeiteten wir mit unserer VM pgsql3.sercive.site (über die wir kürzlich berichteten). Wir verschoben die PostgreSQL-Instanz, wobei es zu Unterbrechung von lediglich 2,5 Sekunden kam. Dabei handelte es sich um den Moment, als die VM von einem zum anderen Rechenzentrum transferiert wurde.
Das Migrieren einer virtuellen Maschine
Die folgende Aufzeichnung des Tests zeigt, wie wir pgsql3.sercive.site von esx38.service.site auf esx40.service.site verschieben.
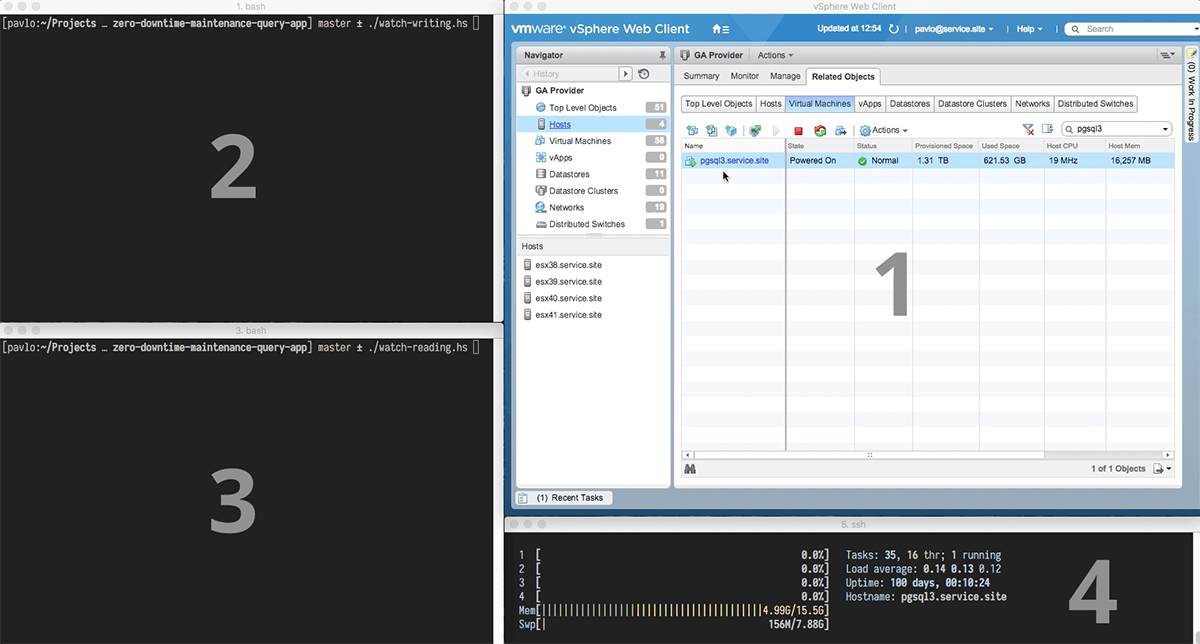
- Fenster 1 ist die Administrationsoberfläche für alle Aufgaben, die unsere Techniker regelmäßig an der Cloud vornehmen müssen. In diesem Fall wird dort die Migration ausgelöst.
- In Fenster 2 läuft ein Programm, das die Datenbank auf pgsql3.service.site verbindet und die Inhalte einer Tabelle mit einer stetig wachsenden immer wieder überschreibt.
- Parallel läuft im Fenster 3 ein Programm, das die Ergebnisse vom Programm darüber ausliest, um sicherzustellen, dass die Daten auch wieder gelesen werden können.
- Das Fenster 4 dient schließlich zur Überwachung der Leistung von pgsql3.service.site.
Sollten wir mehrere virtuelle Maschinen gleichzeitig umziehen müssen, sorgt unser Hypervisor-Management-System dafür, dass nicht zu viele Migrationen zur gleichen Zeit erfolgen, um eine Überlastung des Systems zu vermeiden.
Videoaufzeichnung des Migrationsprozesses**
Bereit für die Wartung
In dem hier geschilderten Test benötigten wir insgesamt 26 Sekunden, um die VM von einem Rechenzentrum in das andere zu verschieben. In der Enterprise Advanced Cloud für unsere Kunden sorgt außerdem das Speichersystem dafür, dass in beiden Rechenzentren permanent eine Replikation der Daten gemacht wird. Der Hypervisor muss sich daher überhaupt nicht darum kümmern. Alle Daten werden simultan während des gesamten Prozesses an beiden Standorten gespeichert. Nur deshalb ist es uns möglich, die Migration ohne Ausfallzeit und ohne jeglichen Datenverlust durchzuführen.
Derzeit sind wir der einzige Cloud-Anbieter in Deutschland mit einer derart robusten Technologie, die garantiert, dass unsere Kunden keinerlei Ausfallzeiten hinnehmen müssen – selbst wenn sie zahlreiche Anwendungen auf unseren VM laufen lassen.
* Dieser Screenshot zeigt aktuelle Aufälle von S3 am 14. September 2017.
** Sie finden die Beispielprogramme, die im Video zu sehen sind auf unserer GitHub-Seite: https://github.com/global-access/example-zero-downtime-maintenance
*** Ein Artikel über AVMotion-Funktionen findet sich bei VMWare.

