Maintenance of a cloud service often has an unforeseen impact on the customers’ uptime. There are different strategies for dealing with this issue, which primarily depends on the software that is running in the affected cloud. For example, classic software – which was not developed specifically for the cloud – often cannot handle such downtime automatically, so the virtual machines (VM) running the software have to be shut down to prevent data corruption. At Global Access however, we use a special technology that allows us to move running VMs with no service interruption. Thus, any maintenance performed will not affect our cloud customers at all.
In order to keep our cloud infrastructure at the highest standard, our technicians work on its various components on a regular basis. We also use a hypervisor that allows us to move the VM seamlessly, even between the data centers. Most cloud providers, in particular Microsoft Azure and Amazon, use a different hypervisor, and their technology is not capable of seamless VM transfers. The best thing a customer of those providers can do is stop a VM, copy it to a different data center, and then restart the copied VM – a process that can take hours or sometimes even days to complete.
Here is an example of how we utilise this technology to perform maintenance on the Global Access internal infrastructure.
The hardware structure
Our infrastructure is organized to mitigate outages that occur within a data center and also in the case when an entire data center malfunctions. Such outages may be rare, but they will happen to everyone sooner or later.* We run our internal virtual machines on a cluster of four hosts: esx38 and esx39 are in one data center, and esx40 and esx41 are in the other. The cluster for our customers consists of even more servers, but for the purpose of this article, a four-host example will suffice.
Depending on the situation, we move all the VMs before the maintenance begins. For example, when we have to work on hardware or install security updates on a host, we move all the VMs from that server to any other available server. However, if maintenance of the power grid is imminent, we move all the VMs from one data center to the other.
To illustrate an actual maintenance scenario, we’ll use our VM pgsql3.service.site (as described before). We moved the PostgreSQL instance. During this process, there were only 2.5 seconds of downtime, namely the moment when the VM was transferred to a different data center.
Migrating a virtual machine
The following recorded experiment shows how we migrate pgsql3.service.site from esx38.service.site to esx40.service.site. After such a move, we can perform maintenance on hardware that has the potential to cause problems.
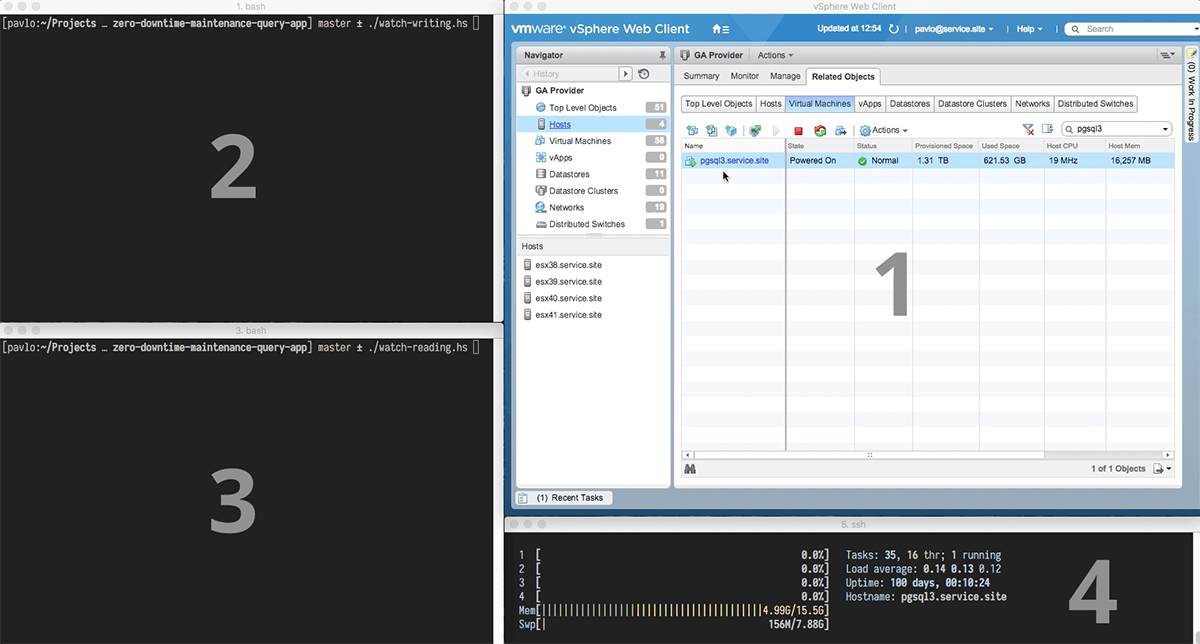
- Window 1 is our administration interface to all the cloud tasks our technicians have to perform on a regular basis. We use it to manage the migration.
- In window 2, we run a program that connects to the example database on pgsql3.service.site and repeatedly replaces the contents of a table with an increasing number from an infinite sequence.
- In parallel, we run a program in window 3 that reads the number from the program above in order to ensure that the data can be retrieved.
- Window 4 displays the performance monitor of pgsql3.service.site.
When we need to migrate multiple virtual machines, our hypervisor management makes sure that too many migrations are not run at the same time and that the system is not overloaded.
Video recording (screen cast) of the entire migration process.**
Ready for maintenance
In the experiment above, it took us 26 seconds to move a VM from one data center to the other. With Enterprise Advanced Cloud, our storage system ensures that the persistent disk state is mirrored to the other data center continuously, so the hypervisor does not have to deal with it at all. All the data is simultaneously stored in both locations throughout the entire process. This is how the migration can occur without any service interruption or data loss.
As of the publication of this article, we are the only cloud provider in Germany who utilises this very resilient technology, which guarantees our customers will not experience any downtime, even when running numerous distributed applications.
* See this screenshot of the recent (14 September 2017) outage of S3.
** You can find the example programs used in video on our GitHub page: https://github.com/global-access/example-zero-downtime-maintenance
*** An article about VMotion features can be found at VMWare.

